

Last update April 22, 2025
This year, I attended the Devoxx convention deep dive days. I was my first time attending such an event and hopefully not the last. I could grab a lot of information in a very short time span. There is something truly different between watching talks or courses at home and being there live (although I’m thankful that we get the opportunity to watch the talks online after the event, as there was a huge list to choose from and I couldn’t attend everything I was interested in).
In this article, I’m sharing a few things that I’ve learnt during these sessions, with links to the talk when available and additional links to dig further.
- Threading lightly with Kotlin by Vasco Veloso
- GraalVM Cloud Native & Micronaut Deep Dive by Graeme Rocher
- Let’s Kustomize our manifests with style by Kevin Davin
- Helm vs Kustomize: the frenemies that soothe Kubernetes by Ana Maria Mihalceanu
- Spring Security demystified by Daniel Garnier-Moiroux
- Ephemeral development environments for a better developer experience by André Duarte
- What’s new in Apollo Kotlin 3 by Martin Bonnin and Benoit Lubek
- Women’s journey in tech by Pooneh Mokariasl
- Improving your skills with the debugger by Bouke Nijhuis
Threading lightly with Kotlin by Vasco Veloso
- People often mix up “parallel” and “concurrent”. Concurrent tasks use the same processor while parallel ones use multiple processors (CPUs).
- There is a difference between the threads handled by the hardware (limited to 16 threads at the moment in most cases) and those handled by the OS (hundreds of threads running). In software development, we play with the software (OS) threads. Two important composants: the scheduler => pre-emptive distribution between CPUs; the registrer => store the point of execution, the state of the thread (threads are stateful).
- Coroutines are different from threads as they’re cooperative (they can allow other coroutines to run), they’re not handled at the same level as threads, the responsibility of running and storing the state is in the hands of our program (not the OS) => in Kotlin it’s handled by the Kotlin runtime library (+ correct calls and constructs in the code).
- In the 60s, coroutines were the go-to solution because there wasn’t so much available CPU. The first real multithreaded OS was Windows NT.
- Coroutines in Kotlin need a scope that allows them to run, otherwise they cannot be called/invoked (runBlocking).
- Coroutines run on threads, which means pausing that thread blocks all coroutines running on it. On the other hand, pausing a coroutine doesn’t block the other coroutines but allows them to run in the meantime.
- Coroutines suspension points are
yield(),delay()(similar to a thread’ssleep()) and calling another coroutine (launch()). Without suspension points, coroutines will just run one after the other. Misuse of suspension points can make processing time longer! - By default, coroutines all run on a single thread, but we can make use of multiple threads for work that is purely CPU-bound.
- Cancelling a coroutine can only happen at suspension points (or with
isActive()but it’s deprecated). Cancellation is cooperative. Cancelling a coroutine also cancels children coroutines (different behavior than threads) => structured concurrency. launch()returns an object implementing the Job interface.- Going concurrent explicitly => use of async/await (non blocking) => returns an object of type Deferred (implements Job). Async allows to get the result back from the coroutine.
- Coroutine scope = aggregation of concurrent coroutines in a single unit. If an exception is raised in one coroutine, all coroutines in scope are cancelled (structured concurrency). Coroutines in a scope can be multi-threaded (depends on the Dispatcher strategy =>
runBlocking(Dispatchers.Default). After suspension, a coroutine could run on a different thread (in multi-threaded case). If no dispatcher is specified, they run on a single thread. - We can use a JVM thread pool to schedule the Kotlin coroutines (.asCoroutineDispatcher()).
- A Generator is a special kind of coroutine that only yields to produce a value and only to its caller. Cold source => intermediate operators => [exceptions propagated] => completes on data end or exception => collect to get result.
- Spring Webflux supports coroutines.
- Gatling => load testing tool for applications (a bit off topic but it was mentioned during this talk).
GraalVM Cloud Native & Micronaut Deep Dive by Graeme Rocher
- Micronaut is a framework oriented to serveless and microservices, but it can be used for any type of application.
- The trend is to smaller, leaner runtimes, and more intelligent compilers (GraalVM, Quarkus, Spring Native) (*this being said by the creator of GraalVM, just to mention it :))
- Kotest => unit tests framework for Kotlin
- GraalVM is multicloud by design.
- Introspection “replaces” Java Reflection and Jackson for serialization. It’s built at compile time. It also means the errors are found and highlighted earlier in the development process (no need to run/fail/read stack trace).
- Service discovery capabilities => use of service ids instead of a url.
- Micronaut Management module => equivalent to Spring Actuator.
- A native image is an image that is made to run on the current OS (executable) => smaller image size.
- Micronaut AOT => convert yaml, xml… to Java so the parsing is not needed anymore => additional performance improvement.
- It’s possible to add the Jackson library or to explicitly allow Reflection (at class or attribute level) if needed (e.g. for a third party library that’d need it).
- Swagger configuration yaml file is created at compile time, no need to run the app to generate it.
- Data is precomputed at runtime => checked at compile time, reflection free (if using the Micronaut libraries). Libraries available at the moment are:
* JPA (Hibernate)
* JDBC (synchronous; support for Java records)
* R2DBC (reactive)
* MongoDB (uses Micronaut serialization; reactive and synchronous implementations)
* Oracle Coherence
The query builder methods of JDBC are checked at compile time - Micronaut 3.7 offers support for Test Containers. (There were several talks and labs about Test Containers that I couldn’t attend, topics seems interesting)
- There are guided tutorials available on Micronaut Guides.
Let’s Kustomize our manifests with style by Kevin Davin
- Kustomize allows to handle configuration for different environments and configuration in a declarative way (same as vanilla Kubernetes, and contrary to helm that’s written in a templated way). If simplifies a bit the syntax of K8s manifests. Modifications are detected at deployment thanks to a digest suffix to only apply new or modified configurations. It can work with helm charts. Overlays allow to add environment specific configurations. Values can be fetched from git.
Helm vs Kustomize: the frenemies that soothe Kubernetes by Ana Maria Mihalceanu
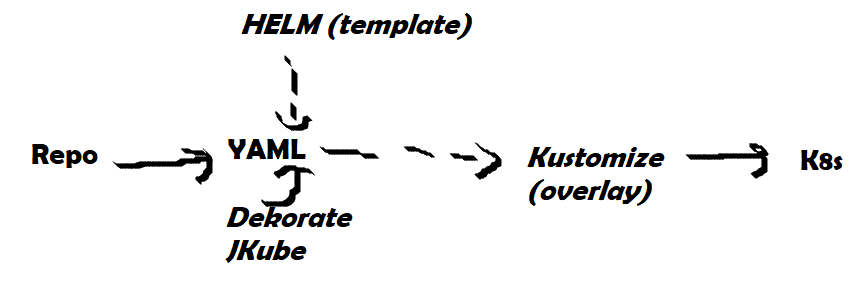
- Cons of Kustomize: not DRY, manual maintenance, embedded kubectl version doesn’t have the latest features.
- kubectl kustomize cfg fmt => solve format problem (indent).
- Cons of Helm: imperative (different from K8s), more abstraction layers, runtime customisation = overhead in CI/CD (but Pro: it’s DRY).
- helm lint => check helm charts for potential issues + dry run.
- Helm charts can be used by Kustomize.
Spring Security demystified by Daniel Garnier-Moiroux
- There is a new (now recommended) way to write the http configuration in the ConfigurerAdapter without method chaining with
.and(), thanks to lambda (although the chained methods will still be supported). Spring Security Lambda DSL - Using emojis in your texts during tests allow to quickly check if there is a problem with the encoding (and thus potential problems with accentuated characters) because emojis are UTF-8 encoded. (Off topic but I liked the tip)
getPrincipal()returns a type Object => compatibility with all authentication methods, but on the other hand it’s not type-safe. It’s always better to use an implementation (e.g. Authentication), as fine-grained as possible. Principal is a Java object and Authentication or other implementations are from Spring Security. It’s also a good practice to create one’s implementation to meet our precise need.- Security context => thread-local, cleaned after request proceeds. When we start a new thread, we “loose” the security context (it’s not passed to the new thread) but when we join the thread with the security context, it still lives there until completed.
- Putting a breakpoint at
DefaultSecurityFilterChainallows to see the list of filters applied. Filters => chain of responsibility pattern. If there are several filter chains, they will be tried sequentially (antMatcher). We can user@Orderto force the order of execution. - We can make custom filters by extending
GenericFilterBean(or one of its descendents) orOncePerRequestFilter(recommended). To add it in the filter chain:addFilterBefore(...). In thedoFilterInternaloverridden method, make a call todoFilterwhen the authentication is ok. - Authentication = authenticated principal or a bundle of credentials that needs to be authenticated.
- AuthenticationProvider => return null to delegate authentication (“I don’t know about this/I have nothing to do with this”).
- AuthenticationSuccessEvent (fired by AuthenticationManager) => ApplicationListener => useful for logging, alerts…
- Prefer composition pattern when defining custom behavior to take benefit of the Spring Security auto-configuration without digging in the code base implementation (avoid inheritance).
Ephemeral development environments for a better developer experience by André Duarte
- According to a survey by InfoWorld, software engineers spend a lot of time* managing their environment. “Software engineers spend lots of time not building software“, InfoWorld (*although I totally agree that development environment management can be a big pain, the survey shows that it “only” accounts for 2.7 hours on a week, being the shortest of all tasks length…)
- Similar solutions exist like GitHub Codespaces or Google Cloud Workstations.
What’s new in Apollo Kotlin 3 by Martin Bonnin and Benoit Lubek
- Codegen
-> operationBased (default) based on graphql operation
-> responseBased based on JSON response
Code generation in Apollo Kotlin - New: better JSON parsing performance done on the fly (removal of an intermediary step), with a few exceptions with operationBased codegen
- SQLite => batching (remove the N+1 problem) => better performance
- AST (abstract syntax tree) = library => expose a full Kotlin representation => query in code instead of graphql query syntax (string)
- Add @nonnull to graphql (nullable by default) at schema or operation level
extra.graphqls => extensions to the schema - Simple way to cache => declarative cache @typePolicy (also in extra.graphqls)
Women’s journey in tech by Pooneh Mokariasl
I didn’t learn much attending this talk, not because it wasn’t interesting but because I’ve already read/listened/watched so much on this topic, but I would definitely recommend the talk to anyone who’s not (very) informed on the topic as it’s a great summary in less than 30 minutes! Still, I would say that I’ve learnt that…
- It seems that not only women care about this topic! I was pleased to see that most of the audience was male (worth to mention that the attendees to the convention were probably 95% male during these two days of deep dive) and that there were questions from them in the end, but also really encouraging reactions on Twitter from male attendees.
Improving your skills with the debugger by Bouke Nijhuis
- It’s possible to set breakpoints without suspension of the execution in IntelliJ (hold
shift+clickto place the breakpoint). - It’s possible to set a customized log text and log a specific value (open breakpoint options then More).
Alt+left clickallow quick evaluation of an expression.- Modifications in the evaluation tools stay in context until execution finishes.
- There is a stream debugging tool that decomposes the operations and the in and out result.
- Reset frame allows to go back in time (in Java context only, not with DB operations).
- Hot swapping doesn’t work for changes in the current method => use reset frame.


