

Last update December 23, 2024
I was given the opportunity to work in a data engineering team, although I had no training or experience in the field. It was really difficult for me figuring out what are the daily tasks of a data engineer before I actually started in that position.
After a year on the job, I realize that the day-to-day work of data engineers is still difficult to summarize and explain. In my opinion, this is because the outcome of data engineering is less tangible than that of software engineering. Also, every DE has a very different experience based on where they work(ed).
In this article I’m sharing what my work as a Data Engineer looked like most days, and what kind of occasional projects I worked on. I will list the tasks in the order I faced them when I transitioned from a Software Engineer to a Data Engineer role.
It’s also worth noting that I was part of a small team with T-shaped skills, meaning we handle the full process of data engineering, either for day-to-day maintenance operations or for time-bound projects. I know some bigger companies have several distinct teams of DEs with a specific scope (step of the data pipeline) each, performing only a part of the workflow I’ll describe here.
The technologies and general rules I’ll share are specific to where I worked and could vary in other companies. When I know some alternatives, I’ll list them.
A very high-level workflow of data warehousing
One of the main responsibilities of Data Engineers is maintaining the data warehouse and data pipelines. The data warehouse is the infrastructure storing the current tables and views. The pipelines can be described in a few big steps:
- Orchestrator. An orchestrator runs data pipelines on a schedule. The orchestrator can be a cloud service or an in-house development. Popular libraries for developing an orchestrator include Airflow and Dagster.
- Services connector. The orchestrator contacts a service that hosts all the connectors and passes parameters to define what to run and how. This service is responsible for authenticating at the sources, triggering the extraction of raw data and writing it to a target (usually a data lake).
This part of the workflow could be handled directly by the orchestrator, but cloud services like Azure Data Factory or Azure Synapse can be used. A big advantage of using cloud services is the direct integration with a secrets vault. - Raw data storage. Raw data is written in a data lake, a vast storage with files written in formats like JSON, Parquet…
- Staging (preparation of data). A staging phase processes the data to make it clean and ready for further transformations. The data is casted (typed), some filters can already be applied, sometimes intermediary tables are already created.
- Final tables creation. Final tables are created by aggregating and joining information coming from different tables, filtering, augmenting data with static information… Multiple tables can be created from the same staged or raw tables, using different calculations, filters, joins… based on the type of facts we want to provide.
- Views creation. Views are created based on the processed table. This is the final stage of the data, where it’s made available for reporting or data science.
If I tried to summarize this in a single sentence, I would say that a Data Engineer collects raw data, that is not usable as-is, from various sources, and processes it to make it usable for the end user.
Data Engineering notions
The way to define relationships between tables is totally different from the one used in transactional databases (the DBs that are used in software engineering most of the time). Here’s a short explanation to understand important concepts like dimension, fact or star schema.
Dimensions and facts
A dimension is a descriptive table for an object. It contains fields such as names, descriptions, other descriptive labels, keys… It’s “repeatable”.
A fact is a table that relates to an occurrence. It describes a relation between different objects at a given time. It contains fields like dates, aggregations, flags, and keys to join dimensions that describe this event. It’s unique.
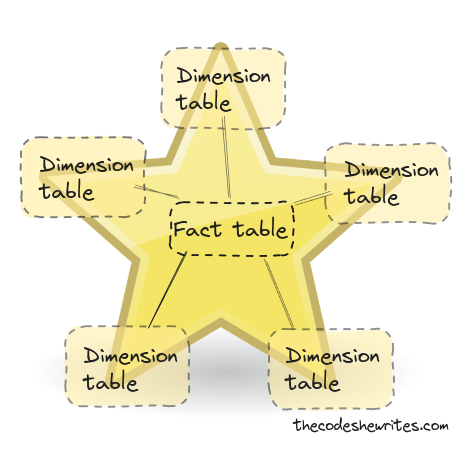
Star schema
A star schema is the most commonly used form of data modelling in data warehousing. The center of the star schema is a fact, and dimensions are the “branches” of the star. Concretely it means that a fact is linked to several dimensions and dimensions are never linked together. (Of course, we can have more or less than 5 dimensions linked to a fact.)
Interested in more? Search for information on Star Schema and Kimball.
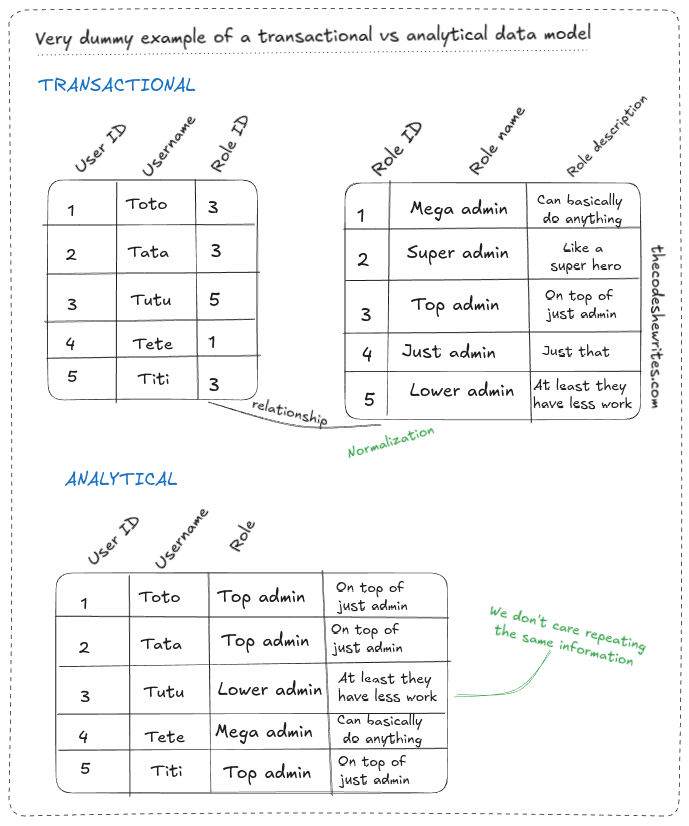
Contrary to what is done in transactional databases, we’re not trying to normalize the model, repetition of the information is not an issue in this kind of model. For example, in a transactional database, a User table would be linked to a Role table. In an analytical database, each row would contain the User with their Role.
Interested in more? Search for the different between OLTP and OLAP)
Day-to-day tasks as a Data Engineer
Develop and maintain custom extractors
Extractors are meant to extract data from different data sources across the company (databases, APIs, connectors to ERPs and CRMs like SAP, Salesforce…, Cloud services, or other tools like Jira, to name only a few). In some cases, the extractor you need doesn’t exist. This is the case when you need to extract data from a peculiar data source, a data source that is not meant to be a data source usually.
Those custom extractors are just software and can be written in any language that supports the necessary operations (making http calls for example). In a DevOps team, the development of any software includes creating the application itself, but also making sure it deploys and runs.
Add columns to an existing table
The most basic type of request is adding some columns in a table that already exists. Depending on the person who wrote the ticket and the kind of source, this can include little to a lot of research to retrieve the fields names in the source (because you have to work with the names provided by the sources, and each has its own standard).
I wrote models with SQL and dbt (a SQL helper with functionalities like macros to reuse some functions for example). The models and data transformation can also be written in a programming language. Some popular languages in Data Engineering are Scala, Java/Kotlin and Python.
Other operations on existing tables include renaming columns, adding filters, deleting or replacing some columns, updating the source column name because the source was modified…
Monitor data pipelines
Sometimes the scheduled data extractions failed. Most of the time, it was because the source was unreachable at the time of the extraction, for a reason out of our control, and I reran the pipeline manually.
Other times, it happened the day after the release, and it usually meant that some breaking changes were released. In that case I had to find the changes that created problems, take corrective actions, or rollback the changes to allow time for investigation.
Another case is a data source that is still unreachable, even after a retry. In such situation, I had to contact the owner of that source to let them know our data pipelines were unable to reach it.
Add new tables (models)
Adding a new table means:
- Designing the model for the table, especially figuring the links between the dimensions and the facts, deciding on the content of those tables, and designing the star schemas to connect the information.
- Sometimes, it required creating a new connector in Azure Data Factory.
- Adding or updating the source configuration in the orchestrator.
- Adding the tables, and sometimes joins to existing tables, in the SQL projects.
It’s also communicating with the requester to make sure they’ll get what they wanted, sometimes creating dummy reports in Power BI yourself to see how the views look and if you can create the necessary links to answer the requester’s questions.
Maintain and create data source connectors
Connectors for data extraction sometimes need to be updated, either because there was a change on the source side, or because the connector version is deprecated. I managed the extractors in Azure Data Factory and the secrets in Azure Keyvault.
New extractors were regularly added because of the integrate new data sources. This required getting an authentication method and some credentials for a service principal (usually provided by another service in the company who’s responsible for the source), choosing the right connector in Data Factory, saving all needed parameters, and designing the workflow for extraction (source, target and intermediate operations).
Review code
As the code (either the extractor applications, or the project holding the models in SQL and dbt) was versioned and integrated into a CI pipeline, I did code reviews too.
Investigate customers’ requests
This means:
- understand what the requester was doing so far (an Excel file, nothing…),
- understand if there is a data source available for the data needed (a database, API, ERP, CRM…),
- define with the requester the actual need (what question needs to be answered based on the data).
Other projects as a Data Engineer
Improve testing and acceptation environments (UAT)
Search for solutions design on how to automate isolated environments, which is much more difficult than in software due to the importance of the data here: you cannot rely that much on mock data! On the other hand, the amount of data is huge, so a full copy is not always possible or desirable.
Migrate queries for logs ingestion
I worked on the migration from Splunk to Azure Data Explorer to ingest logs continuously from connected machines. I translated queries from Splunk QL to KQL (Kusto), added them to a Delta-Kusto project, updated configurations in our data pipeline, created a new connector, updated the configurations and references in our staging and warehouse projects. This project lasted about 6 months (half-time).
Add linters to the SQL/dbt projects
Adding of-the-shelf linters but also developing custom linters, for example to check if Data Engineers wrote their test files for all tables.
Propose process improvements in the team
With experience in Software Engineering, where processes are more standardized and mature than in Data Engineering, I could propose some new ways of working to improve code review, testing, team organization, workflows, automation…
Automate tasks relying on data
Even nowadays, in a lot of companies, it seems that a huge amount of data is still living in Excel files that are updated manually. This is of course very error prone.
A data engineer can then propose new ways of storing data and automating data processes to secure the data quality and allow the business to save a lot of time.
This means understanding the current process, searching for the initial sources of data across the company, creating a structure for data that is potentially not yet stored in a safe and consistent way, train the users and make sure they adopt the new solution, find tools or develop a custom script to automate the transfer of information…
Biggest differences between Data Engineering and Software Engineering
Those are the changes I experienced when moving from a Software Engineer role to Data Engineering, that you might be interested in if you consider changing position (one way or another).
I insist again that it’s particular to the company and team you work in. For example, I’ve heard some data engineers saying they had less contact with the business than software engineers at their company, although it seems odd to me 😅.
Understanding the business
I find it way more important to understand the business in Data Engineering. As a Software developer, I liked understanding what I was working on, but I must recognize it was possible to work with a very shallow understanding most of the time.
In Data Engineering, working on data that doesn’t mean anything to you is really inefficient and error prone, you’d lose a lot of time. Data is really concrete and doesn’t “benefit” from as much abstraction as software does.
This means data will probably require that you have more contacts with the business and take interest in the core business of the company you’re working at.
Technological maturity
The Data Engineering field is way younger than Software Engineering, and it shows. It’s way more difficult to find documentation and especially real use cases on topics such as testing, CI/CD, DataOps… than it is for Software and DevOps.
Due to the nature of the work, it’s rarely possible to just copy/paste what’s done in SE. For example, it usually doesn’t make sense to base Data Engineering tests on mock data!
It means for the moment DE requires more custom solutions development and creativity if you want to apply the same quality grade that is usually observed in Software. This is really important to keep in mind if you consider changing position.
Range of tasks
Data Engineering seems way more diversified in terms of tasks compared to Software Engineering. I was a full stack developer in a DevOps team, but I find myself handling many more different kinds of tasks in my new position.
There might be more technologies and languages to handle in Software Engineering, but there is more tasks diversity in Data Engineering. I would say this is caused by DE covering the daily maintenance of the data warehouse, together with other projects that have a broader scope.
I must also specify that I always worked on long-term projects in Software Engineering, maintaining one or two products at a time. Basically, the maintenance (fixing bugs) felt the same as the new developments (new features), the only tasks that differed a bit were the ones about infrastructure, CI/CD and DevOps.
In Data Engineering, “new features” (developing a new data model) require an investigation phase, the source data and use case is always unique, there’s an analysis phase where you imagine the model, then you implement it (only at that stage we start coding).
When connecting new sources, you could be working with APIs, databases, Cloud services, ERPs… In my experience, the number of APIs and the like with which we integrate is way bigger in data.
For specific projects, you might have to think of new solutions to store the data, you can work on automating tasks… in addition to the usual data warehousing.
Your colleagues will be different
There are very few, if any, Data Engineering specific cursus’s. Data Engineering might require some analytical skills, knowledge of statistics (at least, it can help). It’s also possible to do DE with way less technical knowledge because a lot of tools were developed to allow Data Engineering and Data Science with no code/low code solutions.
Therefore, you will probably work with people that are way less technical savvy than you (if coming from a Software Engineering position). It means you could end up being the most technical person in the team, and having the responsibility to train others, or having to refrain yourself from using some solutions because your colleagues won’t adopt them.
This is also a very important point to take into consideration before switching job: you should investigate what’s the composition of the team and how open they are to technical improvement.
